
CPU缓存行与伪共享
什么是缓存行
不知道你有没有遇到过这么一种情况,有一个二维数组arr[a][b],如果依次遍历arr[0][0...x],速度会很快;而依次遍历arr[0...x][0],速度会比前者慢(甚至差一个数量级)。大家都知道多维数组存储的本质依旧是一维数组,第一种情况是顺序访问,而第二种本质上是随机访问,为什么数组随机和顺序访问会有这么大的差距呢?
注:影响内存顺序和随机I/O性能的原因还有很多,本文介绍的Cache Line只是其中一种
CPU Cache
通常情况下,存储器价格会随着速度的上升而上升,因为高速存储器的成本十分高昂。比如寄存器最快,价格也最贵;内存慢许多,价格也便宜很多。而寄存器与内存的速度差异十分巨大,因此CPU就引入了速度和价格都在二者中间的CPU缓存来平衡这种差异。
一个CPU核心通常会有一个一级缓存L1 Cache,多个核心又共用一个稍大的L2 Cache,现代的CPU往往还有三级缓存L3 Cache。级数越大,容量越大,速度也越慢。
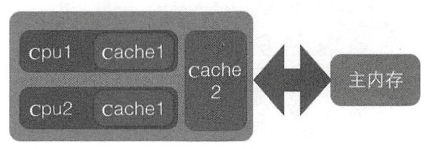
Cache内部的数据是按行存储的,每一行称为一个Cache行。Cache行是Cache与主内存进行数据交换的基本单位,大小一般为2的幕次数字节。

CPU访问变量的方式与缓存行
当CPU尝试访问某个变量时,会先在L1 Cache中查找,如果命中缓存则直接使用;如果没有找到,就去下一级,一直到内存,随后将该变量所在的一个Cache行大小的区域复制到Cache中。查找的路线越长,速度也越慢,因此频繁访问的数据应当保持在L1Cache中。另外,一个变量的大小往往小于一个Cache行的大小,这时就有可能把多个变量放到一个Cache行中。
缓存行带来的好处
最显而易见的好处莫过于对内存的顺序访问了,一个缓存行可能保存多个连续的元素。例如有一个数组arr[100],在访问arr[0]时就会将0下标以及后面的若干个元素放到缓存行中,那么在访问arr[1]及后面的若干个元素时可以直接命中缓存。
代码示例
给出一个经典示例,二维数组在内存中仍然是一维的,arr[x][y] = arr[x*size + y]
情况1是顺序访问,可见缓存行一次Cache了后续多个变量,大幅提升了速度。情况2是跳跃性访问,享受不到这种好处,因为CPU缓存是十分有限的,不可能缓存大量数据,缓存还没有用到就已经被淘汰了。
public class Main {
private static final int SIZE = 10000;
public static void main(String[] args) {
int[][] arr = new int[SIZE][SIZE];
long startTime = System.currentTimeMillis();
for (int i = 0; i < SIZE; i++) {
for (int j = 0; j < SIZE; j++) {
// 情况1 80ms 顺序访问 一次访问后,后面的多次访问都可以命中缓存
arr[i][j] = i * j;
// 情况2 2300ms 随机访问 每次都无法命中缓存行
arr[j][i] = i * j;
}
}
long endTime = System.currentTimeMillis();
System.out.print(endTime - startTime);
}
}
Code language: PHP (php)什么是伪共享
缓存一致性协议
多核CPU的情况下,一个核心就会有一个独立的L1 Cache。假设变量a存在于多个核心的L1 Cache中,此时核心1修改了a,则其他核心的缓存中的a就过期了,必须让其他所有核心缓存中的a都失效。缓存一致性协议就是确保这种情况的。
缓存失效与伪共享
假设我们有两个连续存放(例如数组)的int:a和b,缓存行大小是64字节,则ab可能被存放在一个缓存行中,我们的CPU有两个核心,恰好这两个核心分别在读写这a和b。此时会发生什么情况?
- Core1修改了a,导致Core2存在a的缓存行失效,而ab在一起,也就导致了b的失效
- Core2修改了b,导致Core1存在b的缓存行失效,而ab在一起,也就导致了a的失效
这种因为一个缓存行缓存多个变量,而多个核心又在修改一个缓存行上的多个变量时引发的缓存失效问题,就是伪共享。
如何避免伪共享
避免伪共享的方式往往是进行填充,例如a和b原本可以放到同一个缓存行中,在a的后面填充一些内容,使得a和b无法同时放下,这样来a和b被放到同一个缓存行中。
当然,进行填充势必会造成缓存行存储空间的浪费,因此应当权衡场景,采取正确的策略。
代码演示
代码由N个线程分别频繁访问数组的0-N-1位置的元素
VolatileLong中只有一个被volatile修饰的long变量,多个VolatileLong可能被放在一个缓存行中。
VolatileLong2中的变量前后都有padding变量,多个VolatileLong2不在一个缓存行中。
public class Main {
private final static int CORE_COUNT = Runtime.getRuntime().availableProcessors();
private final static long LOOP = 100 * 1000 * 1000L;
// 6729ms 伪共享
// private static VolatileLong[] longs = new VolatileLong[CORE_COUNT];
// 1460ms 填充解决伪共享问题
private static VolatileLong2[] longs = new VolatileLong2[CORE_COUNT];
public static void main(final String[] args) throws Exception {
for (int i = 0; i < longs.length; i++) {
longs[i] = new VolatileLong2();
}
Thread[] threads = new Thread[Runtime.getRuntime().availableProcessors()];
for (int i = 0; i < threads.length; i++) {
threads[i] = new Thread(new Test(i));
}
long startTime = System.currentTimeMillis();
for (Thread thread : threads) {
thread.start();
}
for (Thread thread : threads) {
thread.join();
}
System.out.println(System.currentTimeMillis() - startTime);
}
static class Test implements Runnable {
private int index = 0;
public Test(int index) {
this.index = index;
}
@Override
public void run() {
long i = LOOP;
while (0 != --i) {
longs[index].value = i;
}
}
}
static class VolatileLong {
public volatile long value = 0L;
}
static class VolatileLong2 {
volatile long i0, i1, i2, i3, i4, i5, i6;
public volatile long value = 0L;
volatile long j0, j1, j2, j3, j4, j5, j6;
}
}
Code language: PHP (php)JDK8以后
JDK8之后,提供了一个@Contended注解,使用它就可以进行自动填充。
例如Thread中就用@Contended,修饰了ThreadLocalRandom的种子,每个线程保存自己的种子。设想一下,如果多个线程的种子被保存在同一个缓存行中,一个线程计算下一个随机数种子值时就会导致其他线程的种子的CPU缓存失效,因此避免这种情况是十分必要的。
/** The current seed for a ThreadLocalRandom */
@sun.misc.Contended("tlr")
long threadLocalRandomSeed;
/** Probe hash value; nonzero if threadLocalRandomSeed initialized */
@sun.misc.Contended("tlr")
int threadLocalRandomProbe;
/** Secondary seed isolated from public ThreadLocalRandom sequence */
@sun.misc.Contended("tlr")
int threadLocalRandomSecondarySeed;
Code language: CSS (css)另外,通常只有JDK的某些实现中才使用@Contented,开发者想要使用,需要在启动时增加一个JVM参数
-XX:-RestrictContended
缓存行有点问题,一个核心对应一个L1 L2,一个CPU中的多个核心共享一个L3
这里是为了描述方便,只能说现代CPU绝大多数是三缓结构,但不应该写死,毕竟过去是二缓,4代移动端酷睿也出现过四缓